
Zunnan Xu
Hi, I am a researcher exploring the intersection of multimodal learning and generative models. Driven by curiosity in my early career, I broadly explored a wide variety of tasks and domains. Building on that foundation, my current research vision is to build a unified perception–generation engine capable of understanding, predicting, and interacting with the physical world. I am always eager to explore new applications—if you have any use cases you would like to share, please feel free to reach out!
News
| 2026 | Two papers accepted to ACL 2026 and ICML 2026. |
|---|---|
| 2025 | Received Outstanding Reviewer Award at Machine Intelligence Research. |
| 2025 | One paper accepted to NeurIPS 2025. |
| 2025 | Two papers accepted to ICCV 2025. |
| 2025 | Received Outstanding Reviewer Award at CVPR 2025. |
| 2025 | Three papers accepted to CVPR 2025. |
| 2024 | One paper accepted to EMNLP 2024. |
| 2024 | Won 3rd prize in CVPR 2024 OVD challenge. |
| 2024 | Two papers accepted to ICML 2024. |
| 2024 | One paper accepted to NeurIPS 2024. |
| 2023 | One paper accepted to ICCV 2023. |
Selected Publications
(* denotes equal contribution)
2D Video & Image Generation
HunyuanPortrait: Implicit condition control for enhanced portrait animation
CVPR 2025
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Technical Report, 2024
Audio-visual controlled video diffusion with masked selective state spaces modeling for natural talking head generation
ICCV 2025
Alignment is All You Need: A Training-free Augmentation Strategy for Pose-guided Video Generation
ICML 2024
Zero-shot 3D-Aware Trajectory-Guided image-to-video generation via Test-Time Training
AAAI 2026

Fireedit: Fine-grained instruction-based image editing via region-aware vision language model
CVPR 2025

InterAnimate: Taming Region-aware Diffusion Model for Realistic Human Interaction Animation
ACMMM 2025
Vision-Language Models

Bridging vision and language encoders: Parameter-efficient tuning for referring image segmentation
ICCV 2023
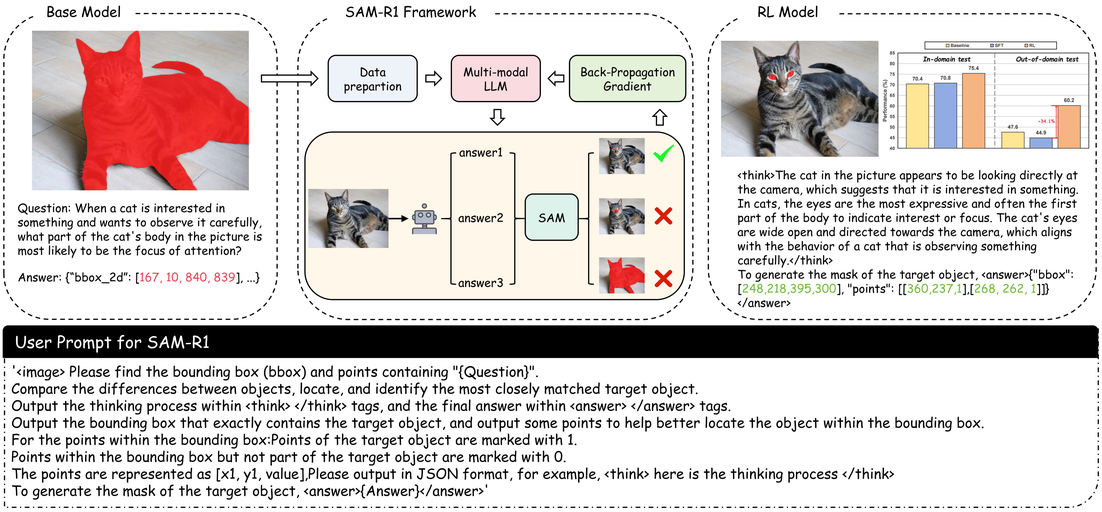
SAM-R1: Leveraging SAM for Reward Feedback in Multimodal Segmentation via Reinforcement Learning
NeurIPS 2025
Igniting vlms toward the embodied space
Technical Report, 2025
Enhancing Fine-grained Multi-modal Alignment via Adapters: A Parameter-Efficient Training Framework
ICML 2024
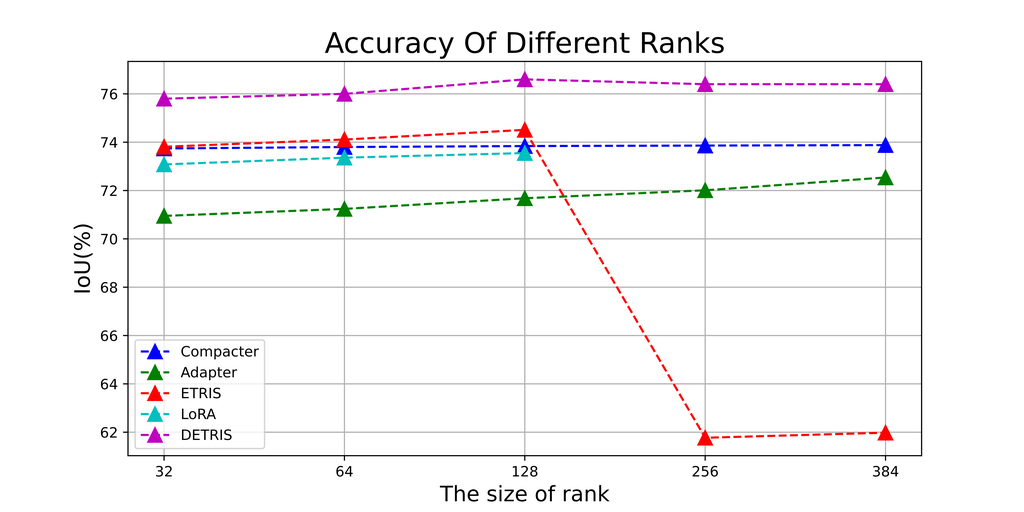
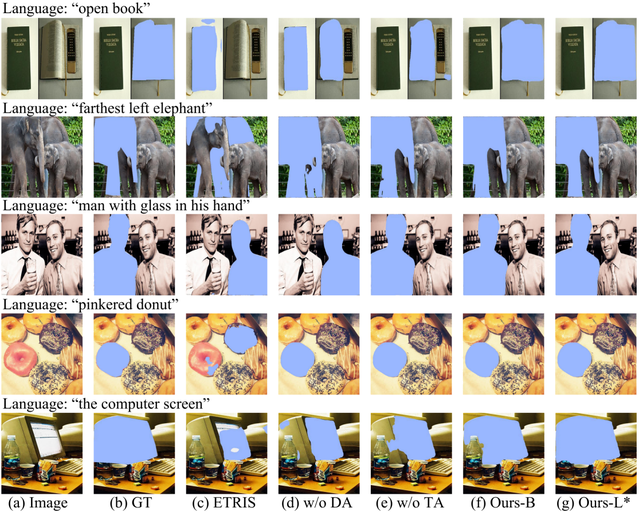
Densely Connected Parameter-Efficient Tuning for Referring Image Segmentation
AAAI 2025

MaPPER: Multimodal Prior-guided Parameter Efficient Tuning for Referring Expression Comprehension
EMNLP 2024
3D Motion Synthesis
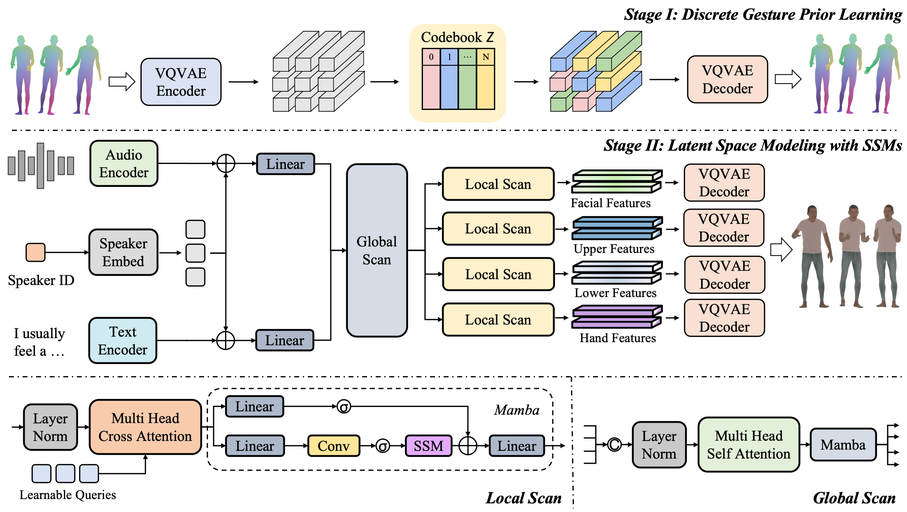
Mambatalk: Efficient holistic gesture synthesis with selective state space models
NeurIPS 2024
Chain of generation: Multi-modal gesture synthesis via cascaded conditional control
AAAI 2024
Separate to Collaborate: Dual-Stream Diffusion Model for Coordinated Piano Hand Motion Synthesis
ACMMM 2025
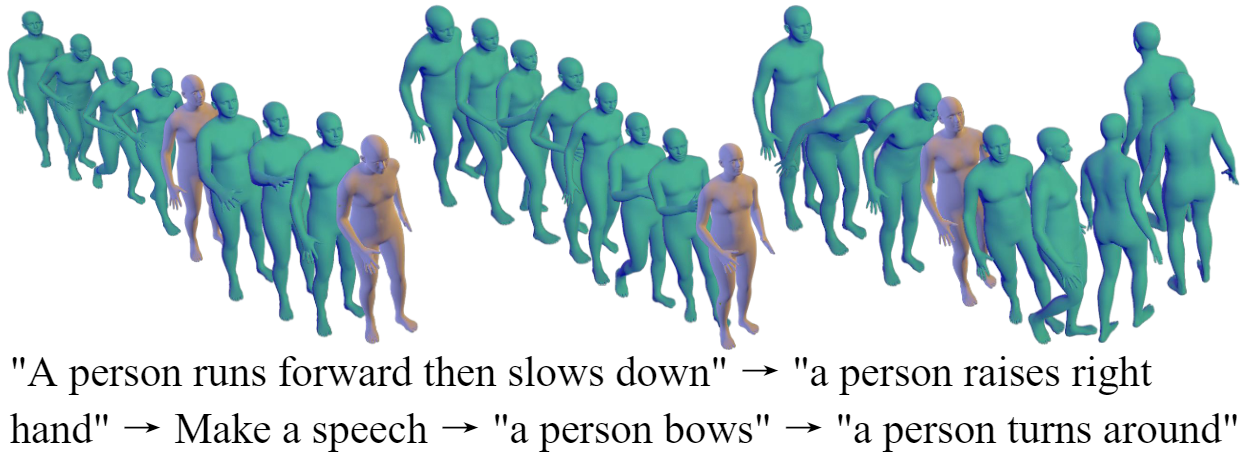
Freetalker: Controllable speech and text-driven gesture generation based on diffusion models
ICASSP 2024
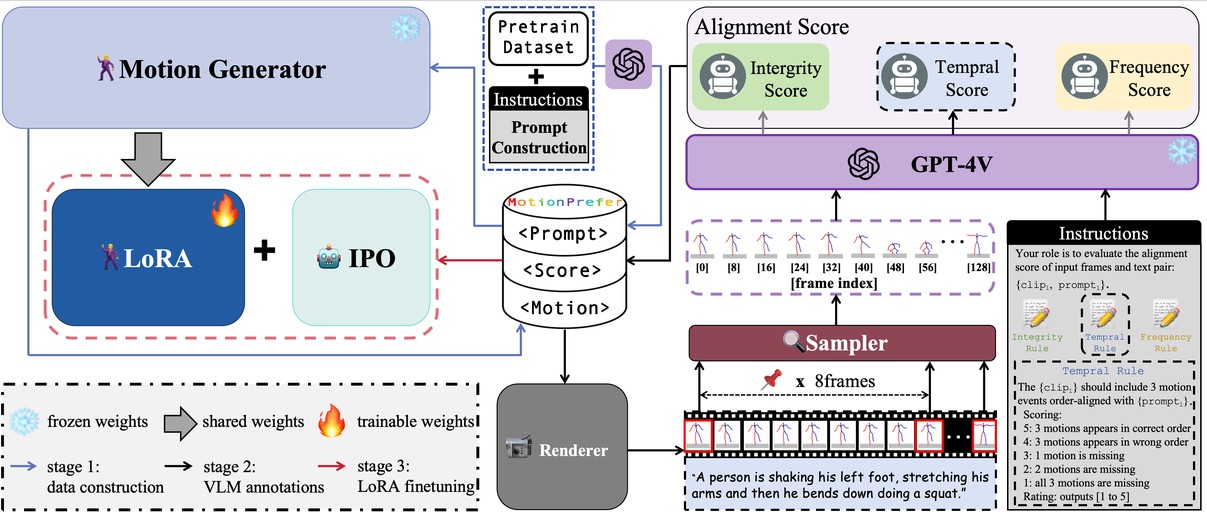
Atom: Aligning text-to-motion model at event-level with gpt-4vision reward
CVPR 2025
3D Generation
Reparo: Compositional 3d assets generation with differentiable 3d layout alignment
ICCV 2025
Consistent123: One image to highly consistent 3d asset using case-aware diffusion priors
ACMMM 2024
Selected Preprint
MIND-V: Hierarchical Video Generation for Long-Horizon Robotic Manipulation with RL-based Physical Alignment
Under Review
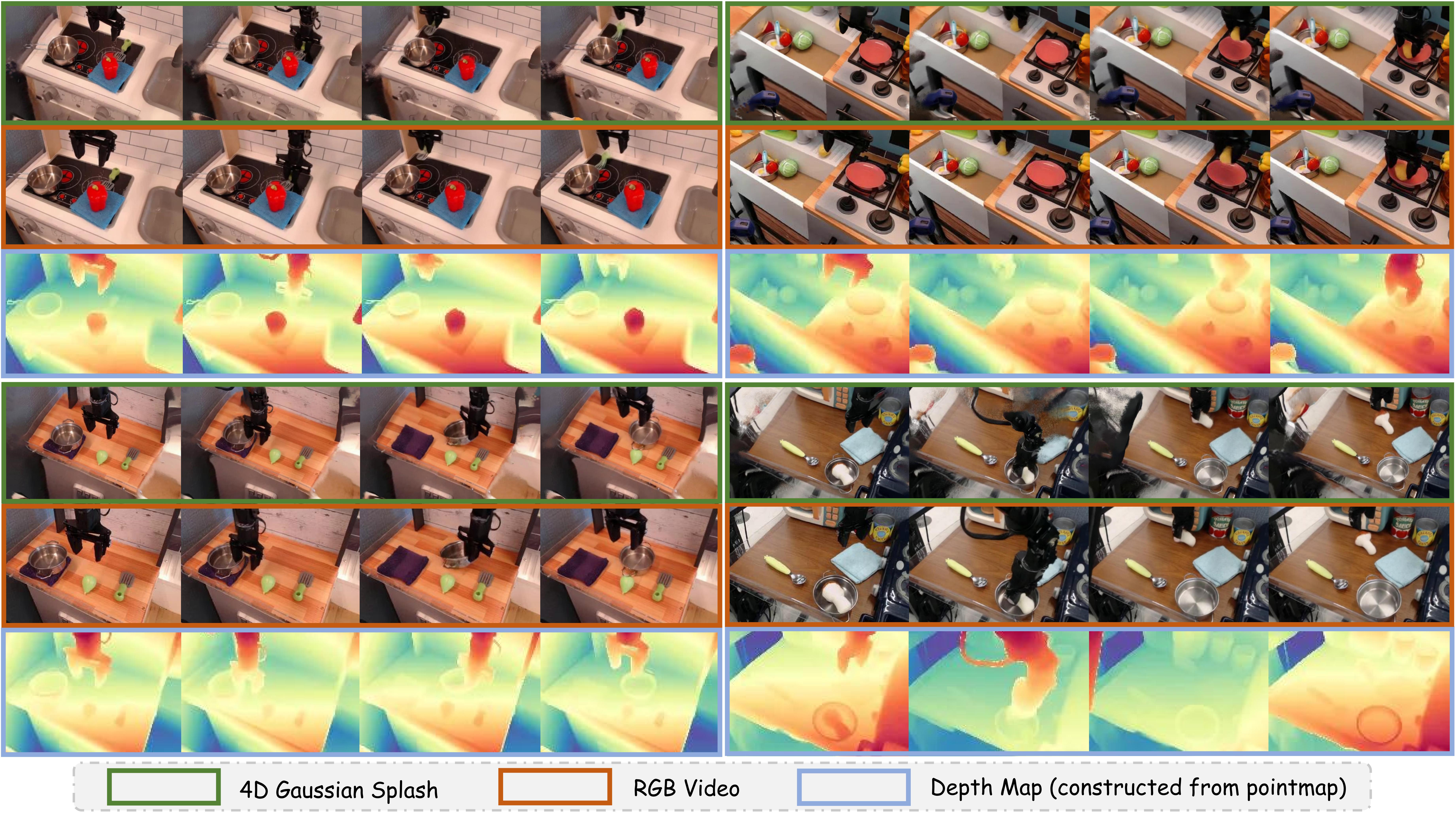
RoboStereo: Dual-Tower 4D Embodied World Models for Unified Policy Optimization
Under Review
Honors & Awards
| 2025 | Outstanding Fellowship of Tencent Rhino-Bird Research Elite Program |
| 2025 | Golden Award in International Exhibition of Inventions Geneva |
| 2025 | Outstanding Graduate of Beijing |
| 2024 | Graduate National Scholarship (Top 0.2%) |
| 2023 | Outstanding Graduate of SYSU with Honors Sash |
| 2022 | Golden Award in iGEM Competition |
| 2021 | Golden Award in ACM/ICPC Competition |
| 2020 | Undergraduate National Scholarship (Top 0.2%) |
Academic Services
Reviewer for:
- Journal: IEEE TPAMI, IEEE TIP, IEEE TMM, IEEE TCSVT, IJCV, TMLR, MIR, AI
- Conference: CVPR, ICCV, SIGGRAPH, NeurIPS, ICML, ICLR, ACL, EMNLP, NAACL, WACV, BMVC, BIBM
